Le fonctionnement du web côté serveur
- Quand une personne visite la page web du site Amazon, elle est téléchargée puis visualisée sur l’ordinateur du client
- C’est ce qui permet de continuer à voir la page même si on n’a plus internet
- L’annuaire de tous les produits d’Amazon est disponible sur le serveur
- Si le client devait stocker tous les produits disponibles sur Amazon sur son ordinateur, il faudrait de très gros disques durs dans chaque ordinateur
- Quand on se connecte sur son compte Amazon, c’est le serveur d’Amazon qui s’occupe de vérifier si le nom d’utilisateur et le mot de passe sont corrects
- Si le client était responsable de dire si oui ou non les identifiants sont corrects, il serait facile de mentir et de se connecter au compte de n’importe qui
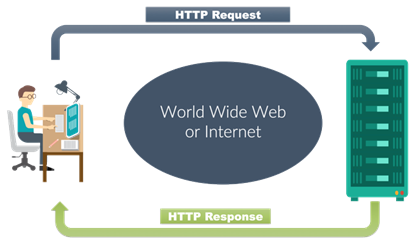
Le serveur répond au client par une flèche nommée "HTTP Response" (réponse HTTP). Au centre est écrit World Wide Web of Internet" que l'on abrège souvent en "web".
Caractéristiques du développement web côté serveur (appelé aussi « back »)
- Ne jamais faire confiance aux données envoyées, toujours vérifier
- Langage algorithmique obligatoire
- S’occupe du stockage de l’information dans une base de données
- S’occupe de la sécurité des informations
Langages algorithmiques usuels côté serveur
- PHP : voir notre fiche dédiée au langage PHP.
- JavaScript (oui, JavaScript peut être client ou serveur) : voir notre fiche dédiée au langage JavaScript.
- Java : voir notre fiche dédiée au langage Java.
- C# : voir notre fiche dédiée au langage C#.
- Python : voir notre fiche dédiée au langage Python.
Langages de requête usuels côté serveur
- SQL : voir notre fiche dédiée au langage SQL.
- Expressions régulières